
Full table of contents¶
User guide¶
This user guide covers using CKAN’s web interface to organize, publish and find data. CKAN also has a powerful API (machine interface), which makes it easy to develop extensions and links with other information systems. The API is documented in API guide.
Some web UI features relating to site administration are available only to users with sysadmin status, and are documented in Sysadmin guide.
What is CKAN?¶
CKAN is a tool for making open data websites. (Think of a content management system like WordPress - but for data, instead of pages and blog posts.) It helps you manage and publish collections of data. It is used by national and local governments, research institutions, and other organizations who collect a lot of data.
Once your data is published, users can use its faceted search features to browse and find the data they need, and preview it using maps, graphs and tables - whether they are developers, journalists, researchers, NGOs, citizens, or even your own staff.
Datasets and resources¶
For CKAN purposes, data is published in units called “datasets”. A dataset is a parcel of data - for example, it could be the crime statistics for a region, the spending figures for a government department, or temperature readings from various weather stations. When users search for data, the search results they see will be individual datasets.
A dataset contains two things:
- Information or “metadata” about the data. For example, the title and publisher, date, what formats it is available in, what license it is released under, etc.
- A number of “resources”, which hold the data itself. CKAN does not mind what format the data is in. A resource can be a CSV or Excel spreadsheet, XML file, PDF document, image file, linked data in RDF format, etc. CKAN can store the resource internally, or store it simply as a link, the resource itself being elsewhere on the web. A dataset can contain any number of resources. For example, different resources might contain the data for different years, or they might contain the same data in different formats.
Users, organizations and authorization¶
CKAN users can register user accounts and log in. Normally (depending on the site setup), login is not needed to search for and find data, but is needed for all publishing functions: datasets can be created, edited, etc by users with the appropriate permissions.
Normally, each dataset is owned by an “organization”. A CKAN instance can have any number of organizations. For example, if CKAN is being used as a data portal by a national government, the organizations might be different government departments, each of which publishes data. Each organization can have its own workflow and authorizations, allowing it to manage its own publishing process.
An organization’s administrators can add individual users to it, with different roles depending on the level of authorization needed. A user in an organization can create a dataset owned by that organization. In the default setup, this dataset is initially private, and visible only to other users in the same organization. When it is ready for publication, it can be published at the press of a button. This may require a higher authorization level within the organization.
Datasets cannot normally be created except within organizations. It is possible, however, to set up CKAN to allow datasets not owned by any organization. Such datasets can be edited by any logged-in user, creating the possibility of a wiki-like datahub.
Note
The user guide covers all the main features of the web user interface (UI). In practice, depending on how the site is configured, some of these functions may be slightly different or unavailable. For example, in an official CKAN instance in a production setting, the site administrator will probably have made it impossible for users to create new organizations via the UI. You can try out all the features described at http://demo.ckan.org.
Using CKAN¶
Registering and logging in¶
Note
Registration is needed for most publishing features and for personalization features, such as “following” datasets. It is not needed to search for and download data.
To create a user ID, use the “Login” link at the top of any page. CKAN will forward you to SOI login page. You will be prompted to select either Public or Employee account. Select and enter the information:
- Username – This should be either illinois.gov or public.external.illinois.gov account. For example, “illinois\testuser” or “central\testuser (if you are part of trusted domain)”.
- Password – enter the same password in both boxes

If there are problems with any of the fields, service will tell you the problem and enable you to correct it. When the fields are filled in correctly, CKAN will create your user account and/or automatically log you in. If you do not have an account please select to create a new one and follow the prompts.
Note
Please note you will need get in touch with State Data Practice @ “DoIT.SDP.Support@illinois.gov” to request organization administration and data publishing roles. Please submit ESR to DoIT helpdesk together with below information:
- Username
- Organization Name
- Access Type
- Justification
Features for publishers¶
Adding a new dataset¶
Note
You will need to be a member of an organization in order to add and edit datsets. On http://demo.ckan.org, you can add a dataset without being in an organization, but dataset features relating to authorization and organizations will not be available.
Step 1. You can access CKAN’s “Create dataset” screen in two ways.
- Select the “Datasets” link at the top of any page. From this, above the search box, select the “Add Dataset” button.
- Alternatively, select the “organizations” link at the top of a page. Now select the page for the organization that should own your new dataset. Provided that you are a member of this organization, you can now select the “Add Dataset” button above the search box.
Step 2. CKAN will ask for the following information about your data. (The actual data will be added in step 4.)
- Title – this title will be unique across CKAN, so make it brief but specific. E.g. “UK population density by region” is better than “Population figures”.
- Description – You can add a longer description of the dataset here, including information such as where the data is from and any information that people will need to know when using the data.
- Tags – here you may add tags that will help people find the data and link it with other related data. Examples could be “population”, “crime”, “East Anglia”. Hit the <return> key between tags. If you enter a tag wrongly, you can use its delete button to remove it before saving the dataset.
- License – it is important to include license information so that people know how they can use the data. This field should be a drop-down box. If you need to use a license not on the list, contact your site administrator.
- Organization - If you are a member of any organizations, this drop-down will enable you to choose which one should own the dataset. Ensure the default chosen is the correct one before you proceed. (Probably most users will be in only one organization. If this is you, CKAN will have chosen your organization by default and you need not do anything.)
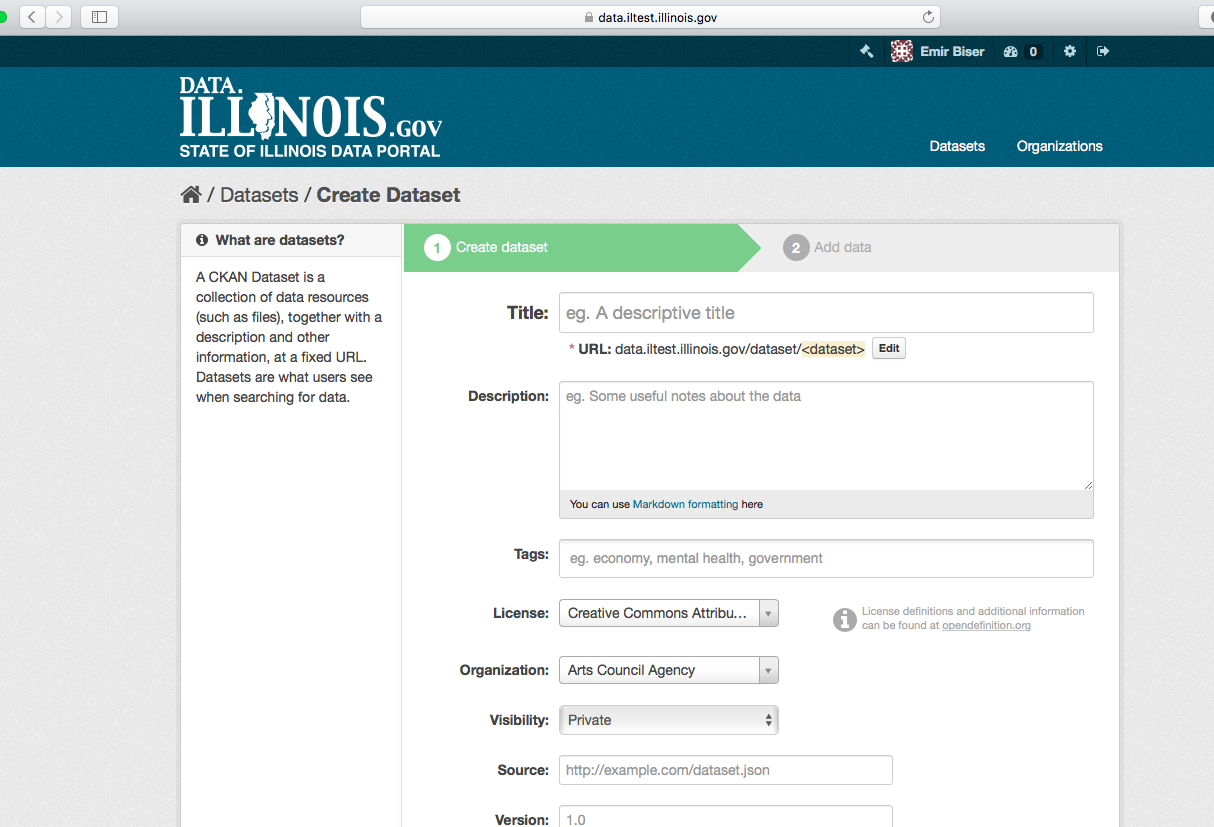
Note
By default, the only required field on this page is the title. However, it is good practice to include, at the minimum, a short description and, if possible, the license information. You should ensure that you choose the correct organization for the dataset, since at present, this cannot be changed later. You can edit or add to the other fields later.
Step 3. When you have filled in the information on this page, select the “Next: Add Data” button. (Alternatively select “Cancel” to discard the information filled in.)
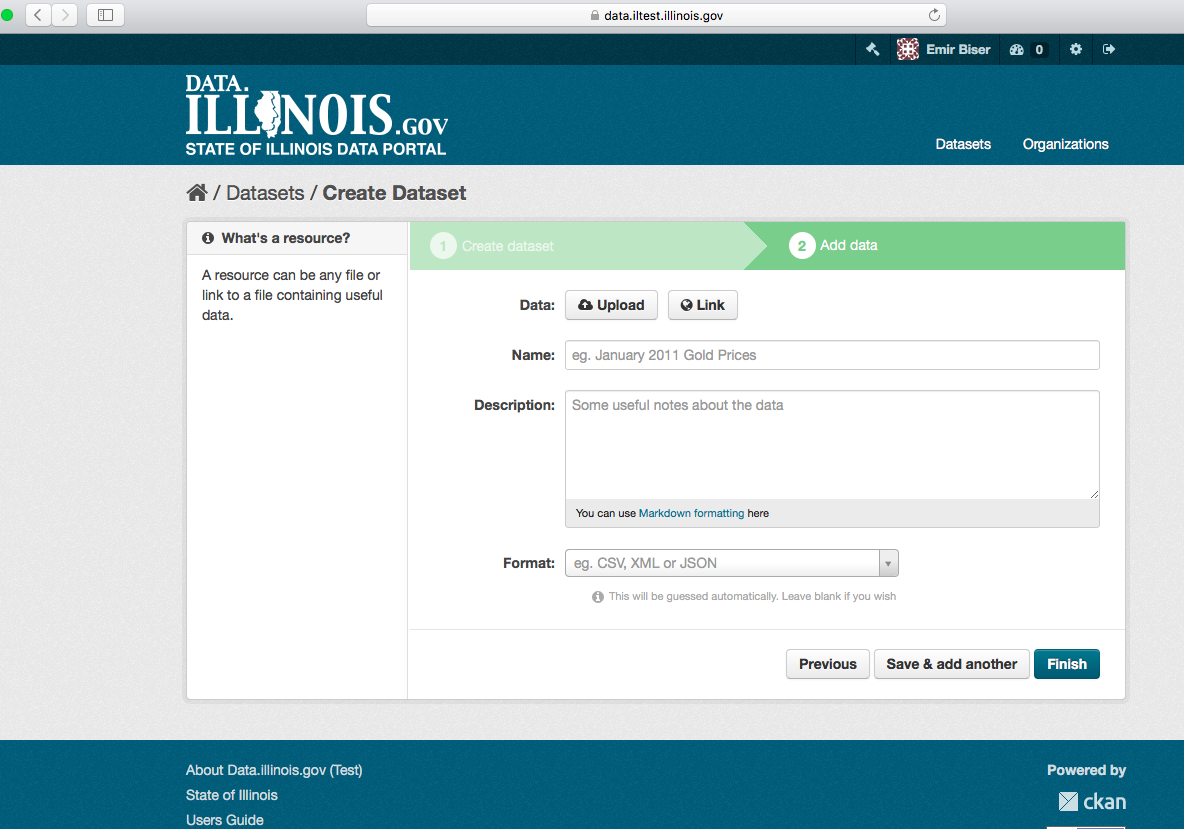
Step 4. CKAN will display the “Add data” screen.

This is where you will add one or more “resources” which contain the data for this dataset. Choose a file or link for your data resource and select the appropriate choice at the top of the screen:
- If you are giving CKAN a link to the data, like http://example.com/mydata.csv, then select “Link to a file” or “Link to an API”. (If you don’t know what an API is, you don’t need to worry about this option - select “Link to a file”.)
- If the data to be added to CKAN is in a file on your computer, select “Upload a file”. CKAN will give you a file browser to select it.
Step 5. Add the other information on the page. CKAN does not require this information, but it is good practice to add it:
- Name – a name for this resource, e.g. “Population density 2011, CSV”. Different resources in the dataset should have different names.
- Description – a short description of the resource.
- Format – the file format of the resource, e.g. CSV (comma-separated values), XLS, JSON, PDF, etc.
Step 6. If you have more resources (files or links) to add to the dataset, select the “Save & add another” button. When you have finished adding resources, select “Next: Additional Info”.
Step 7. CKAN displays the “Additional data” screen.
- Visibility – a Public dataset is public and can be seen by any user of the site. A Private dataset can only be seen by members of the organization owning the dataset and will not show up in searches by other users.
- Author – The name of the person or organization responsible for producing the data.
- Author e-mail – an e-mail address for the author, to which queries about the data should be sent.
- Maintainer / maintainer e-mail – If necessary, details for a second person responsible for the data.
- Custom fields – If you want the dataset to have another field, you can add the field name and value here. E.g. “Year of publication”. Note that if there is an extra field that is needed for a large number of datasets, you should talk to your site administrator about changing the default schema and dataset forms.
Note
Everything on this screen is optional, but you should ensure the “Visibility” is set correctly. It is also good practice to ensure an Author is named.
Changed in version 2.2: Previous versions of CKAN used to allow adding the dataset to existing groups in this step. This was changed. To add a dataset to an existing group now, go to the “Group” tab in the Dataset’s page.
Step 8. Select the ‘Finish’ button. CKAN creates the dataset and shows you the result. You have finished!
You should be able to find your dataset by typing the title, or some relevant words from the description, into the search box on any page in your CKAN instance. For more information about finding data, see the section Finding data.
Editing a dataset¶
You can edit the dataset you have created, or any dataset owned by an organization that you are a member of. (If a dataset is not owned by any organization, then any registered user can edit it.)
- Go to the dataset’s page. You can find it by entering the title in the search box on any page.
- Select the “Edit” button, which you should see above the dataset title.
- CKAN displays the “Edit dataset” screen. You can edit any of the fields (Title, Description, Dataset, etc), change the visibility (Private/Public), and add or delete tags or custom fields. For details of these fields, see Adding a new dataset.
- When you have finished, select the “Update dataset” button to save your changes.
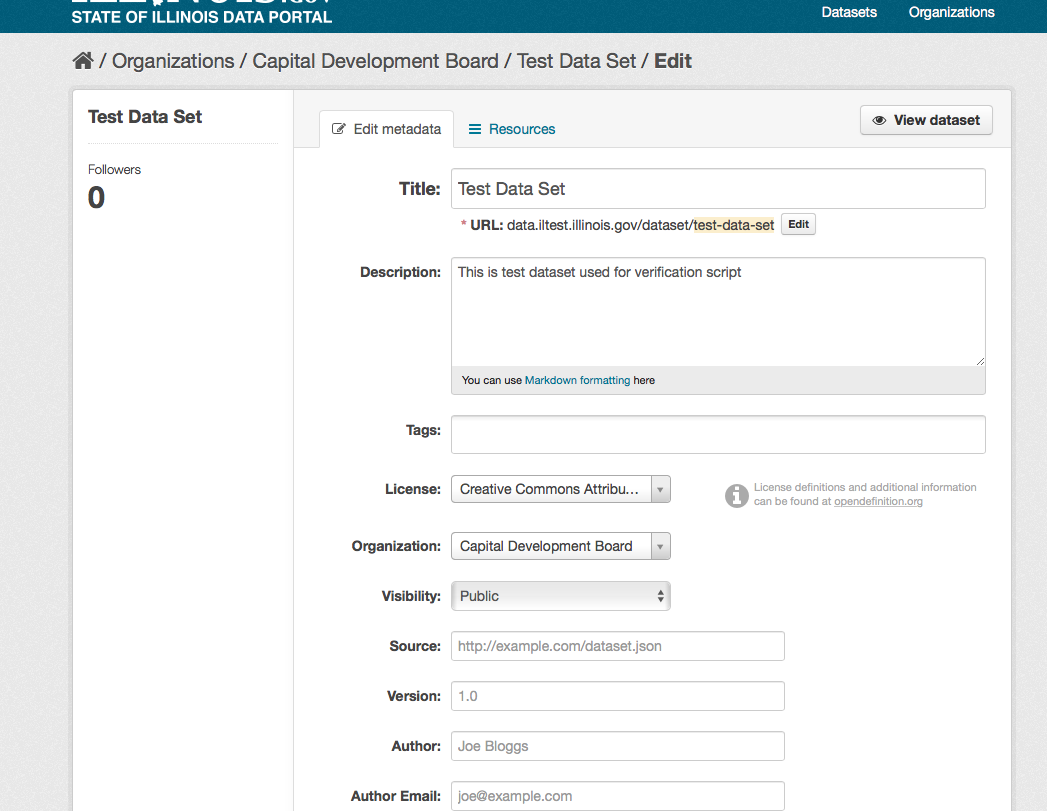
Adding, deleting and editing resources¶
- Go to the dataset’s “Edit dataset” page (steps 1-2 above).
- In the left sidebar, there are options for editing resources. You can select an existing resource (to edit or delete it), or select “Add new resource”.
- You can edit the information about the resource or change the linked or uploaded file. For details, see steps 4-5 of “Adding a new resource”, above.
- When you have finished editing, select the button marked “Update resource” (or “Add”, for a new resource) to save your changes. Alternatively, to delete the resource, select the “Delete resource” button.
Deleting a dataset¶
- Go to the dataset’s “Edit dataset” page (see “Editing a dataset”, above).
- Select the “Delete” button.
- CKAN displays a confirmation dialog box. To complete deletion of the dataset, select “Confirm”.
Note
The “Deleted” dataset is not completely deleted. It is hidden, so it does not show up in any searches, etc. However, by visiting the URL for the dataset’s page, it can still be seen (by users with appropriate authorization), and “undeleted” if necessary. If it is important to completely delete the dataset, contact your site administrator.
Managing an organization¶
When you create an organization, CKAN automatically makes you its “Admin”. From the organization’s page you should see an “Admin” button above the search box. When you select this, CKAN displays the organization admin page. This page has two tabs:
- Info – Here you can edit the information supplied when the organization was created (title, description and image).
- Members – Here you can add, remove and change access roles for different users in the organization. Note: you will need to know their username on CKAN.
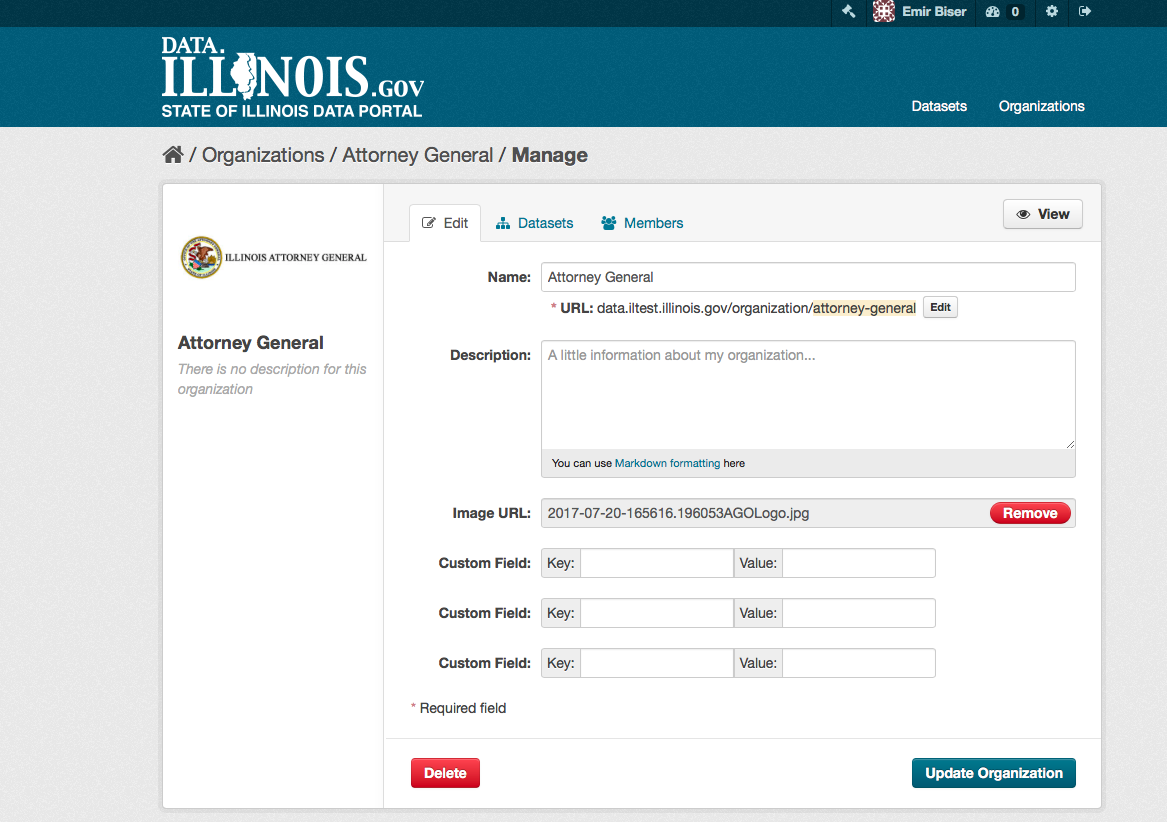
By default CKAN allows members of organizations with three roles:
- Member – can see the organization’s private datasets
- Editor – can edit and publish datasets
- Admin – can add, remove and change roles for organization members
Finding data¶
Searching the site¶
To find datasets in CKAN, type any combination of search words (e.g. “health”, “transport”, etc) in the search box on any page. CKAN displays the first page of results for your search. You can:
- View more pages of results
- Repeat the search, altering some terms
- Restrict the search to datasets with particular tags, data formats, etc using the filters in the left-hand column
If there are a large number of results, the filters can be very helpful, since you can combine filters, selectively adding and removing them, and modify and repeat the search with existing filters still in place.
If datasets are tagged by geographical area, it is also possible to run CKAN with an extension which allows searching and filtering of datasets by selecting an area on a map.
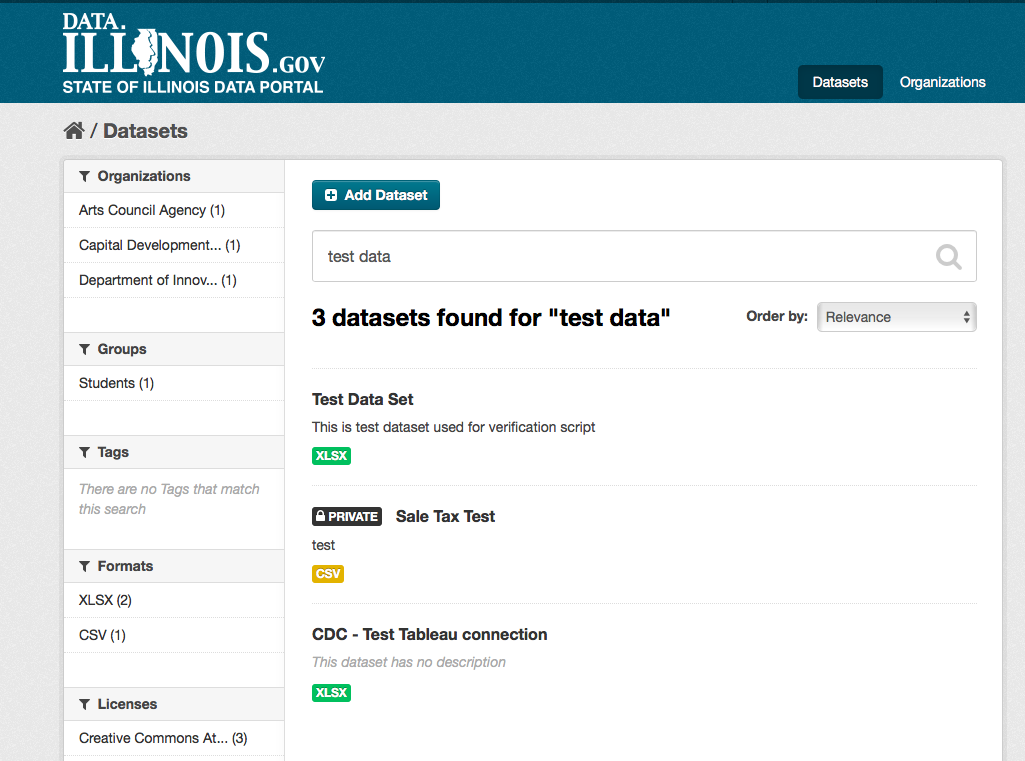
Searching within an organization¶
If you want to look for data owned by a particular organization, you can search within that organization from its home page in CKAN.
- Select the “Organizations” link at the top of any page.
- Select the organization you are interested in. CKAN will display your organization’s home page.
- Type your search query in the main search box on the page.
CKAN will return search results as normal, but restricted to datasets from the organization.
If the organization is of interest, you can opt to be notified of changes to it (such as new datasets and modifications to datasets) by using the “Follow” button on the organization page. You must have a user account and be logged in to use this feature.
Exploring datasets¶
When you have found a dataset you are interested and selected it, CKAN will display the dataset page. This includes
- The name, description, and other information about the dataset
- Links to and brief descriptions of each of the resources
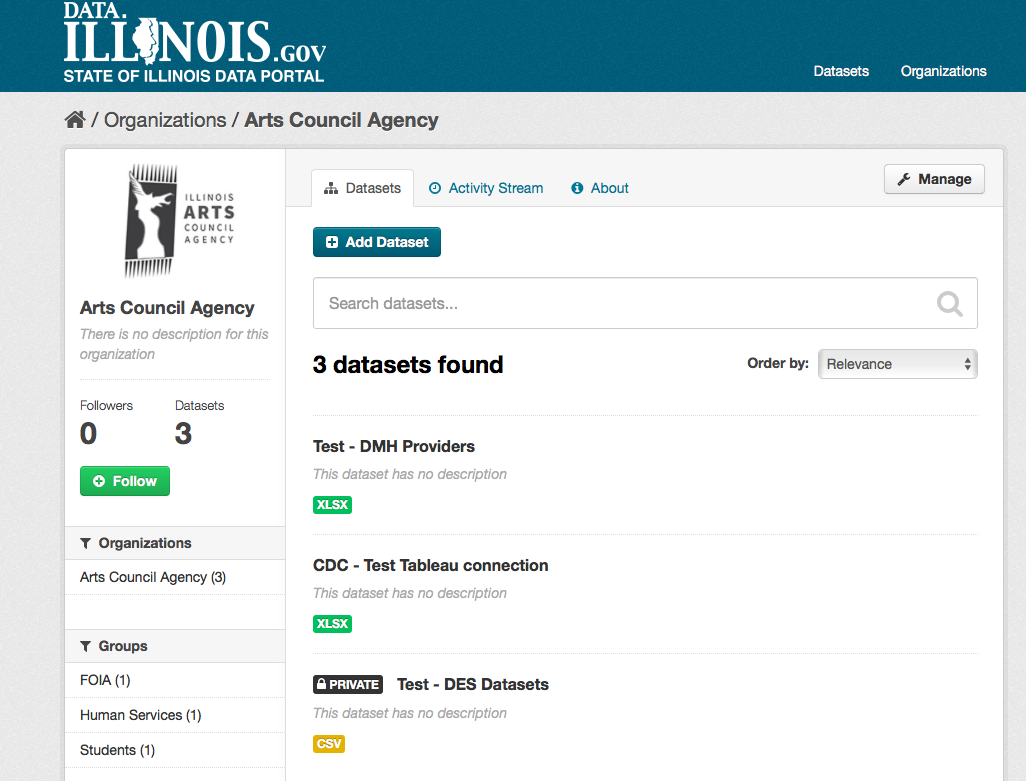
The resource descriptions link to a dedicated page for each resource. This resource page includes information about the resource, and enables it to be downloaded. Many types of resource can also be previewed directly on the resource page. .CSV and .XLS spreadsheets are previewed in a grid view, with map and graph views also available if the data is suitable. The resource page will also preview resources if they are common image types, PDF, or HTML.
The dataset page also has two other tabs:
- Activity stream – see the history of recent changes to the dataset
- Related items – see any links to web pages related to this dataset, or add your own links.
If the dataset is of interest, you can opt to be notified of changes to it by using the “Follow” button on the dataset page. See the section Managing your news feed below. You must have a user account and be logged in to use this feature.
API guide¶
This section documents CKAN’s API, for developers who want to write code that interacts with CKAN sites and their data.
CKAN’s Action API is a powerful, RPC-style API that exposes all of CKAN’s core features to API clients. All of a CKAN website’s core functionality (everything you can do with the web interface and more) can be used by external code that calls the CKAN API. For example, using the CKAN API your app can:
Get JSON-formatted lists of a site’s datasets, groups or other CKAN objects:
http://demo.ckan.org/api/3/action/package_list
Get a full JSON representation of a dataset, resource or other object:
http://demo.ckan.org/api/3/action/package_show?id=adur_district_spending
http://demo.ckan.org/api/3/action/tag_show?id=gold
http://demo.ckan.org/api/3/action/group_show?id=data-explorer
Search for packages or resources matching a query:
http://demo.ckan.org/api/3/action/package_search?q=spending
http://demo.ckan.org/api/3/action/resource_search?query=name:District%20Names
Create, update and delete datasets, resources and other objects
Get an activity stream of recently changed datasets on a site:
http://demo.ckan.org/api/3/action/recently_changed_packages_activity_list
The DataStore API¶
The CKAN DataStore offers an API for reading, searching and filtering data without the need to download the entire file first. The DataStore is an ad hoc database which means that it is a collection of tables with unknown relationships. This allows you to search in one DataStore resource (a table in the database) as well as queries across DataStore resources.
Data can be written incrementally to the DataStore through the API. New data can be inserted, existing data can be updated or deleted. You can also add a new column to an existing table even if the DataStore resource already contains some data.
Triggers may be added to enforce validation, clean data as it is loaded or even record record histories. Triggers are PL/pgSQL functions that must be created by a sysadmin.
You will notice that we tried to keep the layer between the underlying PostgreSQL database and the API as thin as possible to allow you to use the features you would expect from a powerful database management system.
A DataStore resource can not be created on its own. It is always required to have an associated CKAN resource. If data is stored in the DataStore, it will automatically be previewed by the preview extension.
Making a DataStore API request¶
Making a DataStore API request is the same as making an Action API request: you post a JSON dictionary in an HTTP POST request to an API URL, and the API also returns its response in a JSON dictionary.
API reference¶
Note
Lists can always be expressed in different ways. It is possible to use lists, comma separated strings or single items. These are valid lists: ['foo', 'bar'], 'foo, bar', "foo", "bar" and 'foo'. Additionally, there are several ways to define a boolean value. True, on and 1 are all vaid boolean values.
Note
The table structure of the DataStore is explained in Internal structure of the database.
- ckanext.datastore.logic.action.datastore_create(context, data_dict)¶
Adds a new table to the DataStore.
The datastore_create action allows you to post JSON data to be stored against a resource. This endpoint also supports altering tables, aliases and indexes and bulk insertion. This endpoint can be called multiple times to initially insert more data, add fields, change the aliases or indexes as well as the primary keys.
To create an empty datastore resource and a CKAN resource at the same time, provide resource with a valid package_id and omit the resource_id.
If you want to create a datastore resource from the content of a file, provide resource with a valid url.
See Fields and Records for details on how to lay out records.
Parameters: - resource_id (string) – resource id that the data is going to be stored against.
- force (bool (optional, default: False)) – set to True to edit a read-only resource
- resource (dictionary) – resource dictionary that is passed to resource_create(). Use instead of resource_id (optional)
- aliases (list or comma separated string) – names for read only aliases of the resource. (optional)
- fields (list of dictionaries) – fields/columns and their extra metadata. (optional)
- records (list of dictionaries) – the data, eg: [{“dob”: “2005”, “some_stuff”: [“a”, “b”]}] (optional)
- primary_key (list or comma separated string) – fields that represent a unique key (optional)
- indexes (list or comma separated string) – indexes on table (optional)
- triggers (list of dictionaries) – trigger functions to apply to this table on update/insert. functions may be created with datastore_function_create(). eg: [ {“function”: “trigger_clean_reference”}, {“function”: “trigger_check_codes”}]
Please note that setting the aliases, indexes or primary_key replaces the exising aliases or constraints. Setting records appends the provided records to the resource.
Results:
Returns: The newly created data object. Return type: dictionary See Fields and Records for details on how to lay out records.
- ckanext.datastore.logic.action.datastore_run_triggers(context, data_dict)¶
update each record with trigger
The datastore_run_triggers API action allows you to re-apply exisitng triggers to an existing DataStore resource.
Parameters: resource_id (string) – resource id that the data is going to be stored under. Results:
Returns: The rowcount in the table. Return type: int
- ckanext.datastore.logic.action.datastore_upsert(context, data_dict)¶
Updates or inserts into a table in the DataStore
The datastore_upsert API action allows you to add or edit records to an existing DataStore resource. In order for the upsert and update methods to work, a unique key has to be defined via the datastore_create action. The available methods are:
- upsert
- Update if record with same key already exists, otherwise insert. Requires unique key.
- insert
- Insert only. This method is faster that upsert, but will fail if any inserted record matches an existing one. Does not require a unique key.
- update
- Update only. An exception will occur if the key that should be updated does not exist. Requires unique key.
Parameters: - resource_id (string) – resource id that the data is going to be stored under.
- force (bool (optional, default: False)) – set to True to edit a read-only resource
- records (list of dictionaries) – the data, eg: [{“dob”: “2005”, “some_stuff”: [“a”,”b”]}] (optional)
- method (string) – the method to use to put the data into the datastore. Possible options are: upsert, insert, update (optional, default: upsert)
Results:
Returns: The modified data object. Return type: dictionary
- ckanext.datastore.logic.action.datastore_info(context, data_dict)¶
Returns information about the data imported, such as column names and types.
Return type: A dictionary describing the columns and their types. Parameters: id (A UUID) – Id of the resource we want info about
- ckanext.datastore.logic.action.datastore_delete(context, data_dict)¶
Deletes a table or a set of records from the DataStore.
Parameters: - resource_id (string) – resource id that the data will be deleted from. (optional)
- force (bool (optional, default: False)) – set to True to edit a read-only resource
- filters (dictionary) – filters to apply before deleting (eg {“name”: “fred”}). If missing delete whole table and all dependent views. (optional)
Results:
Returns: Original filters sent. Return type: dictionary
- ckanext.datastore.logic.action.datastore_search(context, data_dict)¶
Search a DataStore resource.
The datastore_search action allows you to search data in a resource. DataStore resources that belong to private CKAN resource can only be read by you if you have access to the CKAN resource and send the appropriate authorization.
Parameters: - resource_id (string) – id or alias of the resource to be searched against
- filters (dictionary) – matching conditions to select, e.g {“key1”: “a”, “key2”: “b”} (optional)
- q (string or dictionary) – full text query. If it’s a string, it’ll search on all fields on each row. If it’s a dictionary as {“key1”: “a”, “key2”: “b”}, it’ll search on each specific field (optional)
- distinct (bool) – return only distinct rows (optional, default: false)
- plain (bool) – treat as plain text query (optional, default: true)
- language (string) – language of the full text query (optional, default: english)
- limit (int) – maximum number of rows to return (optional, default: 100)
- offset (int) – offset this number of rows (optional)
- fields (list or comma separated string) – fields to return (optional, default: all fields in original order)
- sort (string) – comma separated field names with ordering e.g.: “fieldname1, fieldname2 desc”
- include_total (bool) – True to return total matching record count (optional, default: true)
- records_format (controlled list) – the format for the records return value: ‘objects’ (default) list of {fieldname1: value1, ...} dicts, ‘lists’ list of [value1, value2, ...] lists, ‘csv’ string containing comma-separated values with no header, ‘tsv’ string containing tab-separated values with no header
Setting the plain flag to false enables the entire PostgreSQL full text search query language.
A listing of all available resources can be found at the alias _table_metadata.
If you need to download the full resource, read Download resource.
Results:
The result of this action is a dictionary with the following keys:
Return type: A dictionary with the following keys
Parameters: - fields (list of dictionaries) – fields/columns and their extra metadata
- offset (int) – query offset value
- limit (int) – query limit value
- filters (list of dictionaries) – query filters
- total (int) – number of total matching records
- records (depends on records_format value passed) – list of matching results
- ckanext.datastore.logic.action.datastore_search_sql(context, data_dict)¶
Execute SQL queries on the DataStore.
The datastore_search_sql action allows a user to search data in a resource or connect multiple resources with join expressions. The underlying SQL engine is the PostgreSQL engine. There is an enforced timeout on SQL queries to avoid an unintended DOS. DataStore resource that belong to a private CKAN resource cannot be searched with this action. Use datastore_search() instead.
Note
This action is only available when using PostgreSQL 9.X and using a read-only user on the database. It is not available in legacy mode.
Parameters: sql (string) – a single SQL select statement Results:
The result of this action is a dictionary with the following keys:
Return type: A dictionary with the following keys
Parameters: - fields (list of dictionaries) – fields/columns and their extra metadata
- records (list of dictionaries) – list of matching results
- ckanext.datastore.logic.action.datastore_make_private(context, data_dict)¶
Deny access to the DataStore table through datastore_search_sql().
This action is called automatically when a CKAN dataset becomes private or a new DataStore table is created for a CKAN resource that belongs to a private dataset.
Parameters: resource_id (string) – id of resource that should become private
- ckanext.datastore.logic.action.datastore_make_public(context, data_dict)¶
Allow access to the DataStore table through datastore_search_sql().
This action is called automatically when a CKAN dataset becomes public.
Parameters: resource_id (string) – if of resource that should become public
- ckanext.datastore.logic.action.set_datastore_active_flag(model, data_dict, flag)¶
Set appropriate datastore_active flag on CKAN resource.
Called after creation or deletion of DataStore table.
- ckanext.datastore.logic.action.datastore_function_create(context, data_dict)¶
Create a trigger function for use with datastore_create
Parameters: - name (string) – function name
- or_replace (bool) – True to replace if function already exists (default: False)
- rettype (string) – set to ‘trigger’ (only trigger functions may be created at this time)
- definition (string) – PL/pgSQL function body for trigger function
- ckanext.datastore.logic.action.datastore_function_delete(context, data_dict)¶
Delete a trigger function
Parameters: name (string) – function name
Download resource¶
A DataStore resource can be downloaded in the CSV file format from {CKAN-URL}/datastore/dump/{RESOURCE-ID}.
For an Excel-compatible CSV file use {CKAN-URL}/datastore/dump/{RESOURCE-ID}?bom=true.
Other formats supported include tab-separated values (?format=tsv), JSON (?format=json) and XML (?format=xml). E.g. to download an Excel-compatible tab-separated file use {CKAN-URL}/datastore/dump/{RESOURCE-ID}?format=tsv&bom=true.
Fields¶
Fields define the column names and the type of the data in a column. A field is defined as follows:
{
"id": # a string which defines the column name
"type": # the data type for the column
}
Field types are optional and will be guessed by the DataStore from the provided data. However, setting the types ensures that future inserts will not fail because of wrong types. See Field types for details on which types are valid.
Example:
[
{
"id": "foo",
"type": "int4"
},
{
"id": "bar"
# type is optional
}
]
Records¶
A record is the data to be inserted in a DataStore resource and is defined as follows:
{
"<id>": # data to be set
# .. more data
}
Example:
[
{
"foo": 100,
"bar": "Here's some text"
},
{
"foo": 42
}
]
Field types¶
The DataStore supports all types supported by PostgreSQL as well as a few additions. A list of the PostgreSQL types can be found in the type section of the documentation. Below you can find a list of the most common data types. The json type has been added as a storage for nested data.
In addition to the listed types below, you can also use array types. They are defines by prepending a _ or appending [] or [n] where n denotes the length of the array. An arbitrarily long array of integers would be defined as int[].
- text
- Arbitrary text data, e.g. Here's some text.
- json
- Arbitrary nested json data, e.g {"foo": 42, "bar": [1, 2, 3]}. Please note that this type is a custom type that is wrapped by the DataStore.
- date
- Date without time, e.g 2012-5-25.
- time
- Time without date, e.g 12:42.
- timestamp
- Date and time, e.g 2012-10-01T02:43Z.
- int
- Integer numbers, e.g 42, 7.
- float
- Floats, e.g. 1.61803.
- bool
- Boolean values, e.g. true, 0
You can find more information about the formatting of dates in the date/time types section of the PostgreSQL documentation.
Resource aliases¶
A resource in the DataStore can have multiple aliases that are easier to remember than the resource id. Aliases can be created and edited with the datastore_create() API endpoint. All aliases can be found in a special view called _table_metadata. See Internal structure of the database for full reference.
HTSQL support (not supported in current release)¶
The ckanext-htsql extension adds an API action that allows a user to search data in a resource using the HTSQL query expression language. Please refer to the extension documentation to know more.
Comparison of different querying methods¶
The DataStore supports querying with multiple API endpoints. They are similar but support different features. The following list gives an overview of the different methods.
| datastore_search() | datastore_search_sql() | HTSQL | |
|---|---|---|---|
| Ease of use | Easy | Complex | Medium |
| Flexibility | Low | High | Medium |
| Query language | Custom (JSON) | SQL | HTSQL |
| Join resources | No | Yes | No |
Internal structure of the database¶
The DataStore is a thin layer on top of a PostgreSQL database. Each DataStore resource belongs to a CKAN resource. The name of a table in the DataStore is always the resource id of the CKAN resource for the data.
As explained in Resource aliases, a resource can have mnemonic aliases which are stored as views in the database.
All aliases (views) and resources (tables respectively relations) of the DataStore can be found in a special view called _table_metadata. To access the list, open http://{YOUR-CKAN-INSTALLATION}/api/3/action/datastore_search?resource_id=_table_metadata.
_table_metadata has the following fields:
- _id
- Unique key of the relation in _table_metadata.
- alias_of
- Name of a relation that this alias point to. This field is null iff the name is not an alias.
- name
- Contains the name of the alias if alias_of is not null. Otherwise, this is the resource id of the CKAN resource for the DataStore resource.
- oid
- The PostgreSQL object ID of the table that belongs to name.
Extending DataStore¶
Starting from CKAN version 2.7, backend used in DataStore can be replaced with custom one. For this purpose, custom extension must implement ckanext.datastore.interfaces.IDatastoreBackend, which provides one method - register_backends. It should return dictonary with names of custom backends as keys and classes, that represent those backends as values. Each class supposed to be inherited from ckanext.datastore.backend.DatastoreBackend.
Note
Example of custom implementation can be found at ckanext.example_idatastorebackend
- ckanext.datastore.backend.get_all_resources_ids_in_datastore()¶
Helper for getting id of all resources in datastore.
Uses get_all_ids of active datastore backend.
- exception ckanext.datastore.backend.InvalidDataError¶
Exception that’s raised if you try to add invalid data to the datastore.
For example if you have a column with type “numeric” and then you try to add a non-numeric value like “foo” to it, this exception should be raised.
- class ckanext.datastore.backend.DatastoreBackend¶
Base class for all datastore backends.
Very simple example of implementation based on SQLite can be found in ckanext.example_idatastorebackend. In order to use it, set datastore.write_url to ‘example-sqlite:////tmp/database-name-on-your-choice’
Prop _backend: mapping(schema, class) of all registered backends Prop _active_backend: current active backend - classmethod register_backends()¶
Register all backend implementations inside extensions.
- classmethod set_active_backend(config)¶
Choose most suitable backend depending on configuration
Parameters: config – configuration object Return type: ckan.common.CKANConfig
- classmethod get_active_backend()¶
Return currently used backend
- configure(config)¶
Configure backend, set inner variables, make some initial setup.
Parameters: config – configuration object Returns: config Return type: CKANConfig
- create(context, data_dict)¶
Create new resourct inside datastore.
Called by datastore_create.
Parameters: data_dict – See ckanext.datastore.logic.action.datastore_create Returns: The newly created data object Return type: dictonary
- upsert(context, data_dict)¶
Update or create resource depending on data_dict param.
Called by datastore_upsert.
Parameters: data_dict – See ckanext.datastore.logic.action.datastore_upsert Returns: The modified data object Return type: dictonary
- delete(context, data_dict)¶
Remove resource from datastore.
Called by datastore_delete.
Parameters: data_dict – See ckanext.datastore.logic.action.datastore_delete Returns: Original filters sent. Return type: dictonary
- search(context, data_dict)¶
Base search.
Called by datastore_search.
Parameters: - data_dict – See ckanext.datastore.logic.action.datastore_search
- fields (list of dictionaries) – fields/columns and their extra metadata
- offset (int) – query offset value
- limit (int) – query limit value
- filters (list of dictionaries) – query filters
- total (int) – number of total matching records
- records (list of dictionaries) – list of matching results
Return type: dictonary with following keys
- search_sql(context, data_dict)¶
Advanced search.
Called by datastore_search_sql. :param sql: a single seach statement :type sql: string
Return type: dictonary
Parameters: - fields (list of dictionaries) – fields/columns and their extra metadata
- records (list of dictionaries) – list of matching results
- make_private(context, data_dict)¶
Do not display resource in search results.
Called by datastore_make_private. :param resource_id: id of resource that should become private :type resource_id: string
- make_public(context, data_dict)¶
Enable serch for resource.
Called by datastore_make_public. :param resource_id: id of resource that should become public :type resource_id: string
- resource_exists(id)¶
Define whether resource exists in datastore.
- resource_fields(id)¶
Return dictonary with resource description.
Called by datastore_info. :returns: A dictionary describing the columns and their types.
- resource_info(id)¶
Return DataDictonary with resource’s info - #3414
- resource_id_from_alias(alias)¶
Convert resource’s alias to real id.
Parameters: alias (string) – resource’s alias or id Returns: real id of resource Return type: string
- get_all_ids()¶
Return id of all resource registered in datastore.
Returns: all resources ids Return type: list of strings
- create_function(*args, **kwargs)¶
Called by datastore_function_create action.
- drop_function(*args, **kwargs)¶
Called by datastore_function_delete action.
Legacy APIs¶
Warning
The legacy APIs documented in this section are provided for backwards-compatibility, but support for new CKAN features will not be added to these APIs.
API Versions¶
There are two versions of the legacy APIs. When the API returns a reference to an object, version 1 of the API will return the name of the object (e.g. "river-pollution"), whereas version 2 will return the ID of the object (e.g. "a3dd8f64-9078-4f04-845c-e3f047125028"). Tag objects are an exception, tag names are immutable so tags are always referred to with their name.
You can specify which version of the API to use in the URL. For example, opening this URL in your web browser will list demo.ckan.org’s datasets using API version 1:
http://demo.ckan.org/api/1/rest/dataset
Opening this URL calls the same function using API version 2:
http://demo.ckan.org/api/2/rest/dataset
If no version number is given in the URL then the API defaults to version 1, so this URL will list the site’s datasets using API version 1:
http://demo.ckan.org/api/rest/dataset
Dataset names can change, so to reliably refer to the same dataset over time, you will want to use the dataset’s ID and therefore use API v2. Alternatively, many people prefer to deal with Names, so API v1 suits them.
When posting parameters with your API requests, you can refer to objects by either their name or ID, interchangeably.
Model API¶
Model resources are available at published locations. They are represented with a variety of data formats. Each resource location supports a number of methods.
The data formats of the requests and the responses are defined below.
Model Resources¶
Here are the resources of the Model API.
| Model Resource | Location |
|---|---|
| Dataset Register | /rest/dataset |
| Dataset Entity | /rest/dataset/DATASET-REF |
| Group Register | /rest/group |
| Group Entity | /rest/group/GROUP-REF |
| Tag Register | /rest/tag |
| Tag Entity | /rest/tag/TAG-NAME |
| Rating Register | /rest/rating |
| Dataset Relationships Register | /rest/dataset/DATASET-REF/relationships |
| Dataset Relationships Register | /rest/dataset/DATASET-REF/RELATIONSHIP-TYPE |
| Dataset Relationships Register | /rest/dataset/DATASET-REF/relationships/DATASET-REF |
| Dataset Relationship Entity | /rest/dataset/DATASET-REF/RELATIONSHIP-TYPE/DATASET-REF |
| Dataset’s Revisions Entity | /rest/dataset/DATASET-REF/revisions |
| Revision Register | /rest/revision |
| Revision Entity | /rest/revision/REVISION-ID |
| License List | /rest/licenses |
Possible values for DATASET-REF are the dataset id, or the current dataset name.
Possible values for RELATIONSHIP-TYPE are described in the Relationship-Type data format.
Model Methods¶
Here are the methods of the Model API.
| Resource | Method | Request | Response |
|---|---|---|---|
| Dataset Register | GET | Dataset-List | |
| Dataset Register | POST | Dataset | |
| Dataset Entity | GET | Dataset | |
| Dataset Entity | PUT | Dataset | |
| Group Register | GET | Group-List | |
| Group Register | POST | Group | |
| Group Entity | GET | Group | |
| Group Entity | PUT | Group | |
| Tag Register | GET | Tag-List | |
| Tag Entity | GET | Dataset-List | |
| Rating Register | POST | Rating | |
| Rating Entity | GET | Rating | |
| Dataset Relationships Register | GET | Pkg-Relationships | |
| Dataset Relationship Entity | GET | Pkg-Relationship | |
| Dataset Relationships Register | POST | Pkg-Relationship | |
| Dataset Relationship Entity | PUT | Pkg-Relationship | |
| Dataset’s Revisions Entity | GET | Pkg-Revisions | |
| Revision List | GET | Revision-List | |
| Revision Entity | GET | Revision | |
| License List | GET | License-List |
In general:
- GET to a register resource will list the entities of that type.
- GET of an entity resource will show the entity’s properties.
- POST of entity data to a register resource will create the new entity.
- PUT of entity data to an existing entity resource will update it.
It is usually clear whether you are trying to create or update, so in these cases, HTTP POST and PUT methods are accepted by CKAN interchangeably.
Model Formats¶
Here are the data formats for the Model API:
| Name | Format |
|---|---|
| Dataset-Ref | Dataset-Name-String (API v1) OR Dataset-Id-Uuid (API v2) |
| Dataset-List | [ Dataset-Ref, Dataset-Ref, Dataset-Ref, ... ] |
| Dataset | { id: Uuid, name: Name-String, title: String, version: String, url: String, resources: [ Resource, Resource, ...], author: String, author_email: String, maintainer: String, maintainer_email: String, license_id: String, tags: Tag-List, notes: String, extras: { Name-String: String, ... } } See note below on additional fields upon GET of a dataset. |
| Group-Ref | Group-Name-String (API v1) OR Group-Id-Uuid (API v2) |
| Group-List | [ Group-Ref, Group-Ref, Group-Ref, ... ] |
| Group | { name: Group-Name-String, title: String, description: String, packages: Dataset-List } |
| Tag-List | [ Name-String, Name-String, Name-String, ... ] |
| Tag | { name: Name-String } |
| Resource | { url: String, format: String, description: String, hash: String } |
| Rating | { dataset: Name-String, rating: int } |
| Pkg-Relationships | [ Pkg-Relationship, Pkg-Relationship, ... ] |
| Pkg-Relationship | { subject: Dataset-Name-String, object: Dataset-Name-String, type: Relationship-Type, comment: String } |
| Pkg-Revisions | [ Pkg-Revision, Pkg-Revision, Pkg-Revision, ... ] |
| Pkg-Revision | { id: Uuid, message: String, author: String, timestamp: Date-Time } |
| Relationship-Type | One of: ‘depends_on’, ‘dependency_of’, ‘derives_from’, ‘has_derivation’, ‘child_of’, ‘parent_of’, ‘links_to’, ‘linked_from’. |
| Revision-List | [ revision_id, revision_id, revision_id, ... ] |
| Revision | { id: Uuid, message: String, author: String, timestamp: Date-Time, datasets: Dataset-List } |
| License-List | [ License, License, License, ... ] |
| License | { id: Name-String, title: String, is_okd_compliant: Boolean, is_osi_compliant: Boolean, tags: Tag-List, family: String, url: String, maintainer: String, date_created: Date-Time, status: String } |
To send request data, create the JSON-format string (encode in UTF8) put it in the request body and send it using PUT or POST.
Response data will be in the response body in JSON format.
Notes:
- When you update an object, fields that you don’t supply will remain as they were before.
- To delete an ‘extra’ key-value pair, supply the key with JSON value: null
- When you read a dataset, some additional information is supplied that you cannot modify and POST back to the CKAN API. These ‘read-only’ fields are provided only on the Dataset GET. This is a convenience to clients, to save further requests. This applies to the following fields:
| Key | Description |
|---|---|
| id | Unique Uuid for the Dataset |
| revision_id | Latest revision ID for the core Package data (but is not affected by changes to tags, groups, extras, relationships etc) |
| metadata_created | Date the Dataset (record) was created |
| metadata_modified | Date the Dataset (record) was last modified |
| relationships | info on Dataset Relationships |
| ratings_average | |
| ratings_count | |
| ckan_url | full URL of the Dataset |
| download_url (API v1) | URL of the first Resource |
| isopen | boolean indication of whether dataset is open according to Open Knowledge Definition, based on other fields |
| notes_rendered | HTML rendered version of the Notes field (which may contain Markdown) |
Search API¶
Search resources are available at published locations. They are represented with a variety of data formats. Each resource location supports a number of methods.
The data formats of the requests and the responses are defined below.
Search Resources¶
Here are the published resources of the Search API.
| Search Resource | Location |
|---|---|
| Dataset Search | /search/dataset |
| Resource Search | /search/resource |
| Revision Search | /search/revision |
| Tag Counts | /tag_counts |
See below for more information about dataset and revision search parameters.
Search Methods¶
Here are the methods of the Search API.
| Resource | Method | Request | Response |
|---|---|---|---|
| Dataset Search | POST | Dataset-Search-Params | Dataset-Search-Response |
| Resource Search | POST | Resource-Search-Params | Resource-Search-Response |
| Revision Search | POST | Revision-Search-Params | Revision-List |
| Tag Counts | GET | Tag-Count-List |
It is also possible to supply the search parameters in the URL of a GET request, for example /api/search/dataset?q=geodata&allfields=1.
Search Formats¶
Here are the data formats for the Search API.
| Name | Format |
|---|---|
| Dataset-Search-Params Resource-Search-Params Revision-Search-Params | { Param-Key: Param-Value, Param-Key: Param-Value, ... } See below for full details of search parameters across the various domain objects. |
| Dataset-Search-Response | { count: Count-int, results: [Dataset, Dataset, ... ] } |
| Resource-Search-Response | { count: Count-int, results: [Resource, Resource, ... ] } |
| Revision-List | [ Revision-Id, Revision-Id, Revision-Id, ... ] NB: Ordered with youngest revision first. NB: Limited to 50 results at a time. |
| Tag-Count-List | [ [Name-String, Integer], [Name-String, Integer], ... ] |
The Dataset and Revision data formats are as defined in Model Formats.
Dataset Parameters
| Param-Key | Param-Value | Examples | Notes |
|---|---|---|---|
| q | Search-String | q=geodata
q=government+sweden
q=%22drug%20abuse%22
q=tags:”river pollution”
|
Criteria to search the dataset fields for. URL-encoded search text. (You can also concatenate words with a ‘+’ symbol in a URL.) Search results must contain all the specified words. You can also search within specific fields. |
| qjson | JSON encoded options | [‘q’:’geodata’] | All search parameters can be json-encoded and supplied to this parameter as a more flexible alternative in GET requests. |
| title, tags, notes, groups, author, maintainer, update_frequency, or any ‘extra’ field name e.g. department | Search-String | title=uk&tags=health
department=environment
tags=health&tags=pollution
tags=river%20pollution
|
Search in a particular a field. |
| order_by | field-name (default=rank) | order_by=name | Specify either rank or the field to sort the results by |
| offset, limit | result-int (defaults: offset=0, limit=20) | offset=40&limit=20 | Pagination options. Offset is the number of the first result and limit is the number of results to return. |
| all_fields | 0 (default) or 1 | all_fields=1 | Each matching search result is given as either a dataset name (0) or the full dataset record (1). |
Note
filter_by_openness and filter_by_downloadable were dropped from CKAN version 1.5 onwards.
Note
Only public datasets can be accessed via the legacy search API, regardless of the provided authorization. If you need to access private datasets via the API you will need to use the package_search method of the API guide.
Resource Parameters
| Param-Key | Param-Value | Example | Notes |
|---|---|---|---|
| url, format, description | Search-String | url=statistics.org
format=xls
description=Research+Institute
|
Criteria to search the dataset fields for. URL-encoded search text. This search string must be found somewhere within the field to match. Case insensitive. |
| qjson | JSON encoded options | [‘url’:’www.statistics.org’] | All search parameters can be json-encoded and supplied to this parameter as a more flexible alternative in GET requests. |
| hash | Search-String | hash=b0d7c260-35d4-42ab-9e3d-c1f4db9bc2f0 | Searches for an match of the hash field. An exact match or match up to the length of the hash given. |
| all_fields | 0 (default) or 1 | all_fields=1 | Each matching search result is given as either an ID (0) or the full resource record |
| offset, limit | result-int (defaults: offset=0, limit=20) | offset=40&limit=20 | Pagination options. Offset is the number of the first result and limit is the number of results to return. |
Note
Powerful searching from the command-line can be achieved with curl and the qjson parameter. In this case you need to remember to escapt the curly braces and use url encoding (e.g. spaces become %20). For example:
curl 'http://thedatahub.org/api/search/dataset?qjson=\{"author":"The%20Stationery%20Office%20Limited"\}'
Revision Parameters
| Param-Key | Param-Value | Example | Notes |
|---|---|---|---|
| since_time | Date-Time | since_time=2010-05-05T19:42:45.854533 | The time can be less precisely stated (e.g 2010-05-05). |
| since_id | Uuid | since_id=6c9f32ef-1f93-4b2f-891b-fd01924ebe08 | The stated id will not be included in the results. |
Util API¶
The Util API provides various utility APIs – e.g. auto-completion APIs used by front-end javascript.
All Util APIs are read-only. The response format is JSON. Javascript calls may want to use the JSONP formatting.
dataset autocomplete¶
There an autocomplete API for package names which matches on name or title.
This URL:
/api/2/util/dataset/autocomplete?incomplete=a%20novel
Returns:
{"ResultSet": {"Result": [{"match_field": "title", "match_displayed": "A Novel By Tolstoy (annakarenina)", "name": "annakarenina", "title": "A Novel By Tolstoy"}]}}
tag autocomplete¶
There is also an autocomplete API for tags which looks like this:
This URL:
/api/2/util/tag/autocomplete?incomplete=ru
Returns:
{"ResultSet": {"Result": [{"Name": "russian"}]}}
resource format autocomplete¶
Similarly, there is an autocomplete API for the resource format field which is available at:
/api/2/util/resource/format_autocomplete?incomplete=cs
This returns:
{"ResultSet": {"Result": [{"Format": "csv"}]}}
markdown¶
Takes a raw markdown string and returns a corresponding chunk of HTML. CKAN uses the basic Markdown format with some modifications (for security) and useful additions (e.g. auto links to datasets etc. e.g. dataset:river-quality).
Example:
/api/util/markdown?q=<http://ibm.com/>
Returns:
"<p><a href="http://ibm.com/" target="_blank" rel="nofollow">http://ibm.com/</a>\n</p>"
is slug valid¶
Checks a name is valid for a new dataset (package) or group, with respect to it being used already.
Example:
/api/2/util/is_slug_valid?slug=river-quality&type=package
Response:
{"valid": true}
munge package name¶
For taking an readable identifier and munging it to ensure it is a valid dataset id. Symbols and whitespeace are converted into dashes. Example:
/api/util/dataset/munge_name?name=police%20spending%20figures%202009
Returns:
"police-spending-figures-2009"
munge title to package name¶
For taking a title of a package and munging it to a readable and valid dataset id. Symbols and whitespeace are converted into dashes, with multiple dashes collapsed. Ensures that long titles with a year at the end preserves the year should it need to be shortened. Example:
/api/util/dataset/munge_title_to_name?title=police:%20spending%20figures%202009
Returns:
"police-spending-figures-2009"
munge tag¶
For taking a readable word/phrase and munging it to a valid tag (name). Symbols and whitespeace are converted into dashes. Example:
/api/util/tag/munge?tag=water%20quality
Returns:
"water-quality"
Status Codes¶
Standard HTTP status codes are used to signal method outcomes.
| Code | Name |
|---|---|
| 200 | OK |
| 201 | OK and new object created (referred to in the Location header) |
| 301 | Moved Permanently |
| 400 | Bad Request |
| 403 | Not Authorized |
| 404 | Not Found |
| 409 | Conflict (e.g. name already exists) |
| 500 | Service Error |
Making an API request¶
To call the CKAN API, post a JSON dictionary in an HTTP POST request to one of CKAN’s API URLs. The parameters for the API function should be given in the JSON dictionary. CKAN will also return its response in a JSON dictionary.
One way to post a JSON dictionary to a URL is using the command-line HTTP client HTTPie. For example, to get a list of the names of all the datasets in the data-explorer group on demo.ckan.org, install HTTPie and then call the group_list API function by running this command in a terminal:
http http://demo.ckan.org/api/3/action/group_list id=data-explorer
The response from CKAN will look like this:
{
"help": "...",
"result": [
"data-explorer",
"department-of-ricky",
"geo-examples",
"geothermal-data",
"reykjavik",
"skeenawild-conservation-trust"
],
"success": true
}
The response is a JSON dictionary with three keys:
"success": true or false.
The API aims to always return 200 OK as the status code of its HTTP response, whether there were errors with the request or not, so it’s important to always check the value of the "success" key in the response dictionary and (if success is false) check the value of the "error" key.
Note
If there are major formatting problems with a request to the API, CKAN may still return an HTTP response with a 409, 400 or 500 status code (in increasing order of severity). In future CKAN versions we intend to remove these responses, and instead send a 200 OK response and use the "success" and "error" items.
"result": the returned result from the function you called. The type and value of the result depend on which function you called. In the case of the group_list function it’s a list of strings, the names of all the datasets that belong to the group.
If there was an error responding to your request, the dictionary will contain an "error" key with details of the error instead of the "result" key. A response dictionary containing an error will look like this:
{ "help": "Creates a package", "success": false, "error": { "message": "Access denied", "__type": "Authorization Error" } }
"help": the documentation string for the function you called.
The same HTTP request can be made using Python’s standard urllib2 module, with this Python code:
#!/usr/bin/env python
import urllib2
import urllib
import json
import pprint
# Use the json module to dump a dictionary to a string for posting.
data_string = urllib.quote(json.dumps({'id': 'data-explorer'}))
# Make the HTTP request.
response = urllib2.urlopen('http://demo.ckan.org/api/3/action/group_list',
data_string)
assert response.code == 200
# Use the json module to load CKAN's response into a dictionary.
response_dict = json.loads(response.read())
# Check the contents of the response.
assert response_dict['success'] is True
result = response_dict['result']
pprint.pprint(result)
Example: Importing datasets with the CKAN API¶
You can add datasets using CKAN’s web interface, but when importing many datasets it’s usually more efficient to automate the process in some way. In this example, we’ll show you how to use the CKAN API to write a Python script to import datasets into CKAN.
Todo
Make this script more interesting (eg. read data from a CSV file), and all put the script in a .py file somewhere with tests and import it here.
#!/usr/bin/env python
import urllib2
import urllib
import json
import pprint
# Put the details of the dataset we're going to create into a dict.
dataset_dict = {
'name': 'my_dataset_name',
'notes': 'A long description of my dataset',
}
# Use the json module to dump the dictionary to a string for posting.
data_string = urllib.quote(json.dumps(dataset_dict))
# We'll use the package_create function to create a new dataset.
request = urllib2.Request(
'http://www.my_ckan_site.com/api/action/package_create')
# Creating a dataset requires an authorization header.
# Replace *** with your API key, from your user account on the CKAN site
# that you're creating the dataset on.
request.add_header('Authorization', '***')
# Make the HTTP request.
response = urllib2.urlopen(request, data_string)
assert response.code == 200
# Use the json module to load CKAN's response into a dictionary.
response_dict = json.loads(response.read())
assert response_dict['success'] is True
# package_create returns the created package as its result.
created_package = response_dict['result']
pprint.pprint(created_package)
For more examples, see API Examples.
API versions¶
The CKAN APIs are versioned. If you make a request to an API URL without a version number, CKAN will choose the latest version of the API:
http://demo.ckan.org/api/action/package_list
Alternatively, you can specify the desired API version number in the URL that you request:
http://demo.ckan.org/api/3/action/package_list
Version 3 is currently the only version of the Action API.
We recommend that you specify the API number in your requests, because this ensures that your API client will work across different sites running different version of CKAN (and will keep working on the same sites, when those sites upgrade to new versions of CKAN). Because the latest version of the API may change when a site is upgraded to a new version of CKAN, or may differ on different sites running different versions of CKAN, the result of an API request that doesn’t specify the API version number cannot be relied on.
Authentication and API keys¶
Some API functions require authorization. The API uses the same authorization functions and configuration as the web interface, so if a user is authorized to do something in the web interface they’ll be authorized to do it via the API as well.
When calling an API function that requires authorization, you must authenticate yourself by providing your API key with your HTTP request. To find your API key, login to the CKAN site using its web interface and visit your user profile page.
To provide your API key in an HTTP request, include it in either an Authorization or X-CKAN-API-Key header. (The name of the HTTP header can be configured with the apikey_header_name option in your CKAN configuration file.)
For example, to ask whether or not you’re currently following the user markw on demo.ckan.org using HTTPie, run this command:
http http://demo.ckan.org/api/3/action/am_following_user id=markw Authorization:XXX
(Replacing XXX with your API key.)
Or, to get the list of activities from your user dashboard on demo.ckan.org, run this Python code:
request = urllib2.Request('http://demo.ckan.org/api/3/action/dashboard_activity_list')
request.add_header('Authorization', 'XXX')
response_dict = json.loads(urllib2.urlopen(request, '{}').read())
GET-able API functions¶
Functions defined in ckan.logic.action.get can also be called with an HTTP GET request. For example, to get the list of datasets (packages) from demo.ckan.org, open this URL in your browser:
http://demo.ckan.org/api/3/action/package_list
Or, to search for datasets (packages) matching the search query spending, on demo.ckan.org, open this URL in your browser:
http://demo.ckan.org/api/3/action/package_search?q=spending
Tip
Browser plugins like JSONView for Firefox or Chrome will format and color CKAN’s JSON response nicely in your browser.
The search query is given as a URL parameter ?q=spending. Multiple URL parameters can be appended, separated by & characters, for example to get only the first 10 matching datasets open this URL:
http://demo.ckan.org/api/3/action/package_search?q=spending&rows=10
When an action requires a list of strings as the value of a parameter, the value can be sent by giving the parameter multiple times in the URL:
http://demo.ckan.org/api/3/action/term_translation_show?terms=russian&terms=romantic%20novel
JSONP support¶
To cater for scripts from other sites that wish to access the API, the data can be returned in JSONP format, where the JSON data is ‘padded’ with a function call. The function is named in the ‘callback’ parameter. For example:
http://demo.ckan.org/api/3/action/package_show?id=adur_district_spending&callback=myfunction
Note
This only works for GET requests
API Examples¶
Tags (not in a vocabulary)¶
A list of all tags:
- browser: http://demo.ckan.org/api/3/action/tag_list
- curl: curl http://demo.ckan.org/api/3/action/tag_list
- ckanapi: ckanapi -r http://demo.ckan.org action tag_list
Top 10 tags used by datasets:
- browser: http://demo.ckan.org/api/action/package_search?facet.field=[%22tags%22]&facet.limit=10&rows=0
- curl: curl 'http://demo.ckan.org/api/action/package_search?facet.field=\["tags"\]&facet.limit=10&rows=0'
- ckanapi: ckanapi -r http://demo.ckan.org action package_search facet.field='["tags"]' facet.limit=10 rows=0
All datasets that have tag ‘economy’:
- browser: http://demo.ckan.org/api/3/action/package_search?fq=tags:economy
- curl: curl 'http://demo.ckan.org/api/3/action/package_search?fq=tags:economy'
- ckanapi: ckanapi -r http://demo.ckan.org action package_search fq='tags:economy'
Tag Vocabularies¶
Top 10 tags and vocabulary tags used by datasets:
- browser: http://demo.ckan.org/api/action/package_search?facet.field=[%22tags%22]&facet.limit=10&rows=0
- curl: curl 'http://demo.ckan.org/api/action/package_search?facet.field=\["tags"\]&facet.limit=10&rows=0'
- ckanapi: ckanapi -r http://demo.ckan.org action package_search facet.field='["tags"]' facet.limit=10 rows=0
e.g. Facet: vocab_Topics means there is a vocabulary called Topics, and its top tags are listed under it.
A list of datasets using tag ‘education’ from vocabulary ‘Topics’:
- browser: https://data.hdx.rwlabs.org/api/3/action/package_search?fq=vocab_Topics:education
- curl: curl 'https://data.hdx.rwlabs.org/api/3/action/package_search?fq=vocab_Topics:education'
- ckanapi: ckanapi -r https://data.hdx.rwlabs.org action package_search fq='vocab_Topics:education'
Uploading a new version of a resource file¶
You can use the upload parameter of the resource_update() function to upload a new version of a resource file. This requires a multipart/form-data request, with httpie you can do this using the @file.csv:
http --json POST http://demo.ckan.org/api/3/action/resource_update id=<resource id> upload=@updated_file.csv Authorization:<api key>